
티스토리 뷰
1. Coherent는 serialize에 대해 어떻게 정의하는가?
program order에 맞춰서 serialize된다.
= 프로세서 A가 메모리에 작업한 순서를 프로세서 B도 그대로 느낀다는 말.
2. program order에 대해 좀더 formal하게 말해보자면?
program text나 assembly code에 기술된 순서를 말함.
3. memory consistency model이 말하는 핵심 = 각 load 연산은 어떤 store 연산에 의해 그 값을 리턴받게 되는가?
4. Seqeuntial Consistency의 한계점을 기술하고, 그것을 어떻게 해결했는지 제시해보라.
한번에 하나의 processor만 메모리에 접근할 수 있다.
5. Sequential Consistency가 Modern Architecture에서 실패하는 경우에 대해서 설명해보라.
Modern Architecture는 re-ordering을 허용하는데, 이것은 SC를 만족하는 것을 어렵게 만든다.
6. (T/F) Sequential Consistency는 deterministic policy이다.
F
SC machine은 어떤 processor의 연산을 실행할지 랜덤하게 선택한다. 따라서 non-deterministic
7. SC machine이 생성하는 global ordering은 Sequential Consistency를 가짐.
8. Dekker's Algorithm이 말하는 바는 무엇인가?
Dekker's Algorithm은 Sequential Consistency를 만족할 수 있는 아주 간단한 형태의 로직에 대해 정의하였다.

9. Sequential Consistency가 가지는 한계점을 latency-hiding technique 관점에서 서술해보라.
Seqeuntial Consistency는 latency를 숨기기 위한 작동 기법들, OoO, re-ordering 등에 대해 아주아주 보수적임.
(때로는 memory re-ordering이 아무런 문제를 일으키지 않더라도 SC는 그것을 허용하지 않음.)
그리고 이런 OoO, re-ordering 상황에서는 SC가 correctness를 보장하지 않음.
10. Uniprocessor에서는 Store buffer가 OoO store-load에 대한 우회적인 기법을 제공했다. 하지만, 이것이 multi-processor에서도 통할까?
놉!!
대표적인 실패 사례를 Dekker's Algorithm을 통해 확인해볼 수 있음.
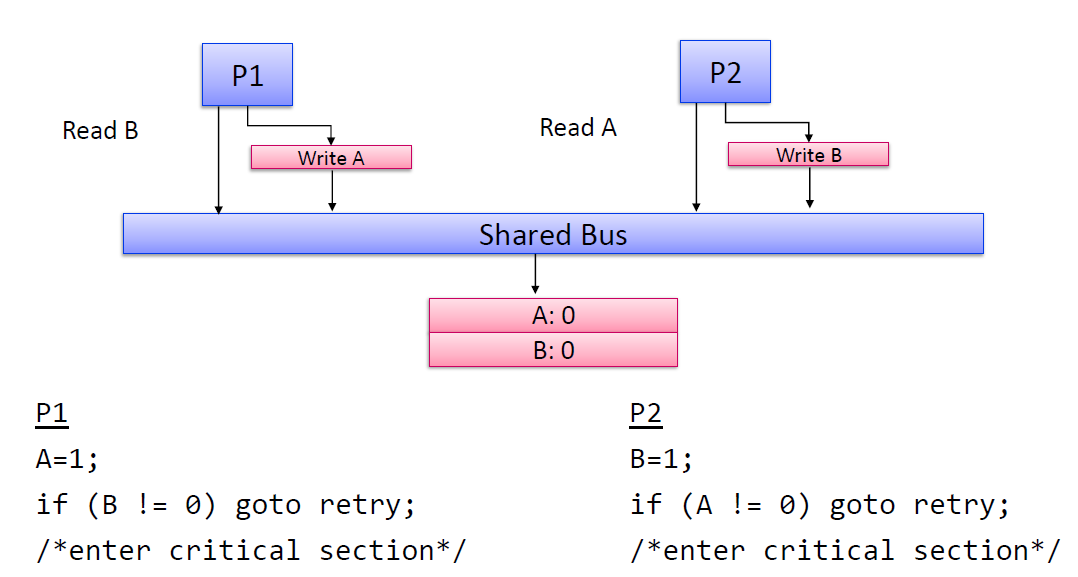
P1의 load는 P2의 store buffer의 값을 볼 수 없음!!
cf) Uniprocessor에서는 load를 하기 전에 항상 store buffer를 체크하여 consistency를 충족시킴.
11. I/O Port Register의 단점에 대해 기술하라.
Port의 수가 정해져 있어, 그 이상의 I/O에 대한 작업을 진행하는 데에 한계점을 가진다.
12. Memory-mapped I/O는 어떻게 memory를 exsternal device에 매핑하는가?
VA는 아주아주 거대한 주소 공간을 가지고 있음. 그래서 사용하지 않는 메모리 영역을 external devices의 register로 매핑함.
13. Memory Idempotency에 대해 간단히 설명해보라. 그리고 I/O에서의 Idempotency에 대해 생각해보라.
메모리 주소 X에 접근하면, 항상 동일한 값을 얻는 성질을 Memory Idempotency라고 한다.
I/O의 경우 대부분의 경우 Idempotency가 성립하지 않는다.
이 Idempotency는 상당히 중요한 성질인데, Idempotency가 만족이 되어야 caching 기술을 쓸 수 있다. I/O는 Idempotency를 만족하지 않기 때문에 우리는 I/O에 대해서는 caching할 수 없는 것이다.
14. cache에서 write가 read보다 더 많은 cycle이 걸리는 이유는 무엇인가?
write는 data bank에 값을 쓰는 행위이기 때문에, tag match 이전에 data bank에 접근하게 되면 문제가 된다.
그래서 tag match HIT를 확인하고(1 cyc), HIT라면 data bank에 접근해서 write를 진행한다(2 cyc)
반면 read의 경우는 좀더 수월한데, tag match HIT를 확인하는 동시에 해당 cache line의 값을 동시에 확인할 수 있다. (1 cyc)
그래서 cache는 write가 read보다 더 오래 걸리게 되는 것이다.
15. partial-word-write가 partial-word-read보다 오래 걸리는 이유를 설명해보라.
16. 지금까지 cache에서 store가 왜 오래걸리는지를 살펴봤다. 하지만 우리는 CPU의 능률을 유지하고 싶다. 어떻게 해결할 수 있을까?
Store Buffer를 도입한다.
그래서 tag가 matching 될 때까지 write할 값을 store buffer에 담아둔다.
17. memory forwarding이란 어떤 상황인지 설명해보라.
store buffer에서 load 연산이 cache가 아닌 store buffer에서 값을 forwarding 받는 것을 말한다.
18. (T/F) "lockup-free" cache는 cache miss 상황에서 blocking 한다.
lockup-free cache는 곧 non-blocking cache이다.
19. (T/F) MSHR의 한 entry는 하나의 cache miss에 대한 정보만을 저장한다.
T
MSHR은 non-blocking cache를 구현하기 위한 핵심임!
20. Back-invalidation problem이란 무엇인지 기술해보라.
Inclusive cache에서 발생하는 문제!!
L2에서 cache block을 evict한다면, L1에서도 해당 cache block이 evict됨.
비록 L1에서 MRU이더라도 L2에서는 LRU이기 때문에 L1은 어쩔 수 없이 MRU를 포기하게 되는 것.
'2020-1 > 컴퓨터 구조' 카테고리의 다른 글
| 컴퓨터 구조(Architecture) 중간고사 범위 점검 퀴즈 (0) | 2020.07.04 |
|---|---|
| Delay Slot: Load Delay Slot & Branch Delay Slot (0) | 2020.07.03 |
| [Cache Coherence] Bus-based Protocol 정리 (0) | 2020.06.24 |
| precise interrupt / imprecise interrupt에 대해 (0) | 2020.05.04 |
| Dynamic Instruction 과 Trace-cache (0) | 2020.05.04 |